

Qu’est ce que le MTBF d’un serveur ? Comment le calculer, où le trouver et surtout, comment l’utiliser pour réduire les risques de panne dans votre infrastructure ? Cet article complet vous explique tout, de la définition au plan de maintenance préventive.
Pourquoi la fiabilité de vos serveurs est un enjeu critique en vidéosurveillance
Un serveur en panne, c’est potentiellement des heures d’enregistrement perdues, des flux vidéo inaccessibles et une infrastructure de sécurité compromise. Pour les professionnels de la vidéosurveillance, la disponibilité de serveurs n’est pas une option : c’est une exigence opérationnelle.
C’est dans ce contexte qu’intervient le MTBF serveur : un indicateur de fiabilité essentiel, encore trop souvent méconnu des équipes IT. Maîtriser cet indicateur, c’est passer d’une gestion réactive des pannes à une approche proactive et structurée.
C’est quoi le MTBF d’un serveur ?
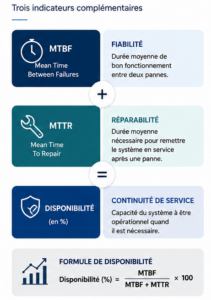
Le MTBF (Mean Time Between Failures, ou temps moyen entre deux pannes) est un indicateur de fiabilité qui mesure la durée moyenne de bon fonctionnement d’un équipement entre deux défaillances successives. Il s’exprime en heures.
Appliqué à un serveur, le MTBF peut concerner l’ensemble du système ou des composants spécifiques : disques durs, alimentations, ventilateurs, cartes mère. Plus le MTBF est élevé, plus le composant est considéré comme fiable statistiquement.
Le MTBF ne s’applique pas uniquement aux serveurs : c’est également une donnée précieuse pour les caméras de vidéosurveillance. Les fabricants publient des MTBF pour leurs caméras IP, dômes motorisés ou caméras extérieures exposées aux intempéries. Intégrer ces données dans votre gestion de parc permet d’anticiper le remplacement des équipements terrain avec la même rigueur que pour vos serveurs.
MTBF vs MTTF : quelle différence ?
Le MTBF s’applique aux composants réparables : après une panne, l’équipement est remis en service et le compteur repart. Le MTTF (Mean Time To Failure) concerne les composants non réparables, remplacés définitivement après défaillance (certains disques durs, par exemple). Ne pas confondre ces deux notions est essentiel pour interpréter correctement les fiches techniques constructeur.
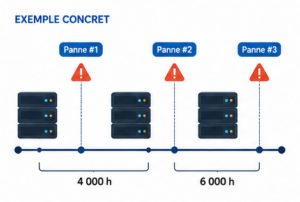
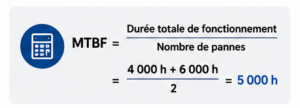
Exemple concret : un serveur affichant un MTBF de 100 000 heures ne tombera pas en panne exactement à ce délai. Il s’agit d’une moyenne statistique calculée sur un grand nombre d’unités en conditions de test. Cela signifie qu’en théorie, sur 100 serveurs identiques, l’un d’eux tombera en panne toutes les 1 000 heures en moyenne.
Comment calculer le MTBF d’un serveur ?
Le calcul du MTBF repose sur une formule simple, appliquée sur une période d’observation définie :
Comment les fabricants calculent-ils le MTBF ?
Les constructeurs (Dell, HP, Lenovo, Supermicro…) déterminent le MTBF en laboratoire, en soumettant des échantillons à des tests de vieillissement accéléré. Ils s’appuient sur des normes reconnues, notamment la MIL-HDBK-217 (norme militaire américaine) et la Telcordia SR-332, qui définissent des modèles de calcul de fiabilité pour les composants électroniques.
Ces valeurs sont théoriques et peuvent s’écarter significativement du MTBF réel observé en conditions d’exploitation (température ambiante, charge CPU, qualité d’alimentation électrique, humidité).
Comment connaître le MTBF de vos serveurs ?
1. Les fiches techniques constructeur
La première source est la datasheet du fabricant. Les MTBF y sont publiés composant par composant : châssis, alimentation, ventilateurs, disques durs. Ces informations sont accessibles sur les sites officiels ou via votre revendeur.
2. Les outils de supervision matérielle
Des solutions embarquées comme iDRAC (Dell), iLO (HP) ou les interfaces IPMI remontent en temps réel des indicateurs de santé matérielle : températures, tensions, état des disques via S.M.A.R.T., durée de vie estimée des alimentations. Ces outils permettent de construire un historique de pannes et de calculer un MTBF empirique propre à votre parc.
3. Votre propre historique d’incidents
Un suivi rigoureux des pannes dans un outil de ticketing ou une CMDB vous permet de calculer un MTBF réel observé, souvent plus représentatif que les données constructeur. C’est la méthode la plus fiable pour piloter la maintenance sur un parc existant.
4. Les outils de diagnostic à distance
Au-delà des interfaces constructeur, il est fortement recommandé de s’appuyer sur des outils de diagnostic à distance pour surveiller l’état de santé de vos équipements en temps réel, sans intervention physique sur site. Ces solutions permettent de détecter des signaux faibles avant qu’ils ne se traduisent par une panne.
eCare a d’ailleurs un développement en cours dans ce domaine, afin de proposer une solution adaptée aux infrastructures de vidéosurveillance.
Les limites du MTBF : ce que l’indicateur ne dit pas
Le MTBF est précieux, mais il ne suffit pas à lui seul. Deux limites majeures à connaître :
Il ne prédit pas quand une panne va survenir. Un serveur avec un MTBF élevé peut tomber en panne dès le premier mois, ou dépasser largement la durée théorique. C’est une probabilité statistique, pas une garantie.
Il ne tient pas compte du temps de remise en service. C’est le rôle du MTTR (Mean Time To Repair). Pour une vision complète, il faut croiser les deux indicateurs via la formule de disponibilité :
Disponibilité (%) = MTBF ÷ (MTBF + MTTR) × 100
Pour une infrastructure de vidéosurveillance où chaque minute d’interruption compte, minimiser le MTTR est aussi important qu’avoir un MTBF élevé. Cela implique de disposer de pièces de rechange, de procédures d’intervention documentées et d’un support réactif.
Pour récapituler, voici un schéma :
MTBF et maintenance préventive : anticiper plutôt que subir
Connaître le MTBF de ses composants permet de planifier la maintenance préventive : remplacer les disques durs, ventilateurs ou alimentations avant d’atteindre les seuils critiques, plutôt qu’intervenir en urgence lors d’une défaillance.
Cette approche réduit les coûts d’intervention, limite les interruptions de service et allonge la durée de vie globale de l’infrastructure. Pour les systèmes de vidéosurveillance, où la continuité d’enregistrement est souvent une obligation contractuelle ou légale, anticiper les défaillances grâce au MTBF est une démarche de professionnalisation de la gestion d’infrastructure.
En complément, des architectures redondantes (RAID, alimentations doubles, serveurs de secours) permettent de maintenir la disponibilité même lorsqu’un composant atteint sa fin de vie.
Failover : aller plus loin dans la sécurisation de votre infrastructure
La redondance matérielle ne suffit pas toujours. Le failover ou le basculement automatique est un mécanisme qui permet de transférer automatiquement les services d’un serveur défaillant vers un serveur de secours, sans interruption perceptible pour les utilisateurs.
Dans un contexte de vidéosurveillance, cela garantit la continuité des enregistrements et l’accessibilité des flux vidéo même en cas de panne matérielle majeure.
Pour en savoir plus sur la mise en œuvre d’une architecture failover adaptée à la vidéosurveillance, consultez notre article dédié : Je découvre l'article sur le failover
FAQ — Questions fréquentes sur le MTBF serveur
Quel est un bon MTBF pour un serveur ?
Les serveurs professionnels affichent généralement des MTBF compris entre 50 000 et 150 000 heures selon les composants. Les disques durs SSD entreprise peuvent dépasser 2 millions d’heures. Ces chiffres sont à interpréter comme des indicateurs relatifs, non comme des garanties absolues.
Le MTBF s’applique-t-il à l’ensemble du serveur ou à ses composants ?
Les deux. Les fabricants publient des MTBF par composant (alimentation, ventilateur, disque dur…). La fiabilité globale du serveur dépend de la combinaison de ces MTBF individuels — un seul composant défaillant peut mettre l’ensemble du système hors service s’il n’y a pas de redondance.
Comment améliorer le MTBF réel de mes serveurs ?
En contrôlant les conditions environnementales (température, humidité, qualité d’alimentation), en appliquant les mises à jour firmware, en mettant en place une surveillance active (iDRAC, iLO, SNMP) et en remplaçant préventivement les composants approchant leur fin de vie théorique.
Conclusion : le MTBF, un levier stratégique pour votre infrastructure de vidéosurveillance
Le MTBF n’est pas qu’un chiffre technique réservé aux équipes IT. C’est un outil de pilotage pour toute organisation qui dépend de la disponibilité de ses serveurs. Bien utilisé, couplé au MTTR et à une stratégie de redondance, il permet de garantir la continuité de service des systèmes critiques.
eCare, vous accompagne dans l’analyse et l’optimisation de leurs infrastructures serveur dédiées à la vidéosurveillance, de la sélection du matériel à la mise en place de plans de maintenance sur mesure.
Votre infrastructure est-elle dimensionnée pour la continuité ?
Nos experts analysent votre parc serveur et vous proposent des recommandations personnalisées pour maximiser votre disponibilité.
Demander un audit gratuitement : J'ai besoin d'un audit gratuit